12강 집약
1. 여러 개의 레코드를 한 개의 레코드로 집약
- SQL의 특징적인 사고방식 중에, 레코드 단위가 아닌 레코드의 '집합' 단위로
처리를 기술하는 것이 있습니다.
-> 이런 사용 방식을 집합 지향(set-oriented)라고 부릅니다.
-> 이러한 특징이 가장 잘 드러나는 때가 GROUP BY 구, HAVING 구와
그것과 함께 사용하는 SUM 또는 COUNT 등의 집약 함수를 사용하는 때입니다.
- SQL에는 집약 함수(aggregate function)이라고 하는,
다른 함수와 구별해서 부르는 함수가 있습니다.
다음 5개의 함수가 바로 집약 함수입니다.
-> COUNT, SUM, AVG, MAX, MIN
- 다음과 같은 비집약 테이블이 있다고 합시다.
CREATE TABLE NonAggTbl
(id VARCHAR(32) NOT NULL,
data_type CHAR(1) NOT NULL,
data_1 INTEGER,
data_2 INTEGER,
data_3 INTEGER,
data_4 INTEGER,
data_5 INTEGER,
data_6 INTEGER);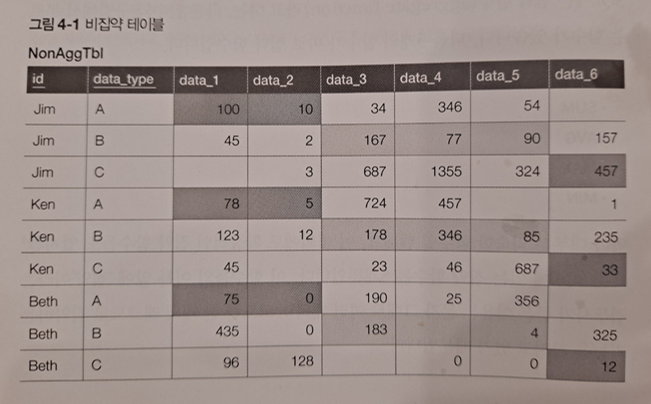
- 이런 비집약 테이블처럼 한 사람과 관련된 정보가 여러 개의 레코드에 분산되어 있는 테이블은,
한 사람의 정보에 접근할 때 'WHERE id=Jim'과 같은 SELECT 구문을 사용할 때,
당연히 3개의 레코드가 선택됩니다.
-> 하지만 이런 데이터를 처리하는 애플리케이션이라면
한 사람에 대한 데이터는 한 개의 레코드로 얻는 것이 편할 것입니다.
-> 따라서 집약 테이블로 만드는 것이 바람직합니다.
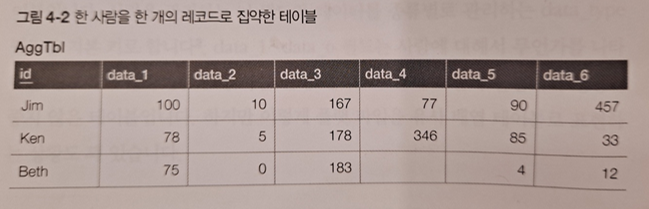
- 비집약 테이블에는 한 사람과 관련된 정보가 여러 레코드에 분산되어 있어서
한 사람의 정보를 참조하려면 여러 레코드에 접근해야 했습니다.
-> 하지만 집약되어 있는 테이블을 보면 한 사람의 정보가 모두 같은 레코드에 들어 있습니다.
-> 따라서 한 사람의 정보를 얻을 때 쿼리 하나면 충분합니다.
1-1) CASE 식과 GROUP BY 응용
- 다음과 같은 쿼리를 작성할 수 있습니다.
SELECT id,
CASE WHEN data_type = 'A' THEN data_1 ELSE NULL END AS data_1,
CASE WHEN data_type = 'A' THEN data_2 ELSE NULL END AS data_2,
CASE WHEN data_type = 'B' THEN data_3 ELSE NULL END AS data_3,
CASE WHEN data_type = 'B' THEN data_4 ELSE NULL END AS data_4,
CASE WHEN data_type = 'B' THEN data_5 ELSE NULL END AS data_5,
CASE WHEN data_type = 'C' THEN data_6 ELSE NULL END AS data_6
FROM NonAggTbl
GROUP BY id;- 이 쿼리는 아쉽게 문법 오류가 발생합니다.
-> GROUP BY 구로 집약했을 때, SELECT 구에서 입력할 수 있는 것은 다음 세 가지 뿐이지만,
현재 CASE 식의 내부에서 사용하고 있는 data_1~data_6는 이 중 어떠한 것에도 해당하지 않습니다.
- 상수
- GROUP BY 구에서 사용한 집약 키
- 집약 함수
- 따라서 집약 함수를 사용해서 다음과 같이 작성해야 합니다.
SELECT id,
MAX(CASE WHEN data_type='A' THEN data_1 ELSE NULL END) AS data_1,
MAX(CASE WHEN data_type='B' THEN data_2 ELSE NULL END) AS data_2,
MAX(CASE WHEN data_type='B' THEN data_3 ELSE NULL END) AS data_3,
MAX(CASE WHEN data_type='B' THEN data_4 ELSE NULL END) AS data_4,
MAX(CASE WHEN data_type='B' THEN data_5 ELSE NULL END) AS data_5,
MAX(CASE WHEN data_type='C' THEN data_6 ELSE NULL END) AS data_6
FROM NonAggTbl
GROUP BY id;- 이러한 집약 쿼리의 실행 계획은
NonAggTbl을 모두 스캔하고 GROUP BY로 집약을 수행하는 단순한 실행 계획입니다.
-> 주목해야 하는 부분은 GROUP BY의 집약 조작에 모두 '해시'라는 알고리즘을 사용하고 있다는 것입니다.
- 최근에는 GROUP BY를 사용하는 집약에서 정렬보다 해시를 사용하는 경우가 많습니다.
-> 이는 GROUP BY 구에 지정되어 있는 필드를 해시 함수를 사용해 해시 키로 변환하고,
같은 해시 키를 가진 그룹을 모아 집약하는 방법입니다.
- GROUP BY와 관련된 성능 주의점을 짚어봅시다.
-> 정렬과 해시 모두 메모리를 많이 사용하므로,
충분한 해시용 워킹 메모리가 확보되지 않으면 스왑이 발생합니다.
-> 따라서 저장소 위의 파일이 사용되면서 굉장히 느려집니다.
2. 합쳐서 하나
- 집약의 이해를 위해 간단한 문제를 풀어봅니다.
-> 다음처럼 '제품의 대상 연령별 가격을 관리하는 테이블'이 있습니다.
-> 문제는 이런 제품 중에 0~100세까지 모든 연령이 가지고 놀 수 있는 제품을 구하라는 것입니다.
CREATE TABLE PriceByAge
(product_id VARCHAR(32) NOT NULL,
low_age INTEGER NOT NULL,
high_age INTEGER NOT NULL,
price INTEGER NOT NULL,
PRIMARY KEY (product_id, low_age),
CHECK (low_age < high_age));
- 일단 집약 단위가 제품이므로 집약 키는 제품 ID로 합니다.
-> 이어서 각 범위에 있는 상수 개수를 모두 더한 합계가 101인 제품을 선택하면 됩니다.
SELECT product_id,
FROM PriceByAge
GROUP BY product_id
HAVING SUM(high_age - low_age + 1) = 101;
13강 자르기
- GROUP BY 구는 집약 이외에도 한 가지 중요한 기능이 더 있습니다.
-> 바로 '자르기'라는 기능입니다.
- 다음과 같이 개인 신체정보를 저장하고 있는 테이블이 있다고 생각합시다.
-> 이 때, 모집합 Persons을 S1~S4의 부분 집합으로 나누고 각각의 부분 집합에
몇 명의 사람이 있는지 알아봅니다.
CREATE TABLE Persons
(name VARCHAR(8) NOT NULL,
age INTEGER NOT NULL,
height FLOAT NOT NULL,
weight FLOAT NOT NULL,
PRIMARY KEY(name));
- 집합의 요소 수를 구할 때는 당연히 COUNT를 사용합니다.
-> name 필드는 기본키이므로 NULL인 경우를 따로 생각할 필요가 없습니다.
(기본 키를 구성하는 필드는 NULL일 수 없습니다.)
-> 이어서 앞 글자를 GROUP BY 구의 키로 지정하면 자르기 완료입니다.
SELECT SUBSTRING(name, 1, 1) AS label,
COUNT(*)
FROM Persons
GROUP BY SUBSTRING(name, 1, 1);
- 이렇게 GROUP BY 구로 잘라 만든 하나하나의 부분 집합을 수학적으로는
'파티션(partition)'이라고 부릅니다.
-> 파티션은 서로 중복되는 요소를 가지지 않는 부분집합입니다.
-> 같은 모집합이라도 파티션을 만드는 방법은 굉장히 많습니다.
- 예를 들어, 나이를 기준으로 어린이(20세 미만), 성인(20세~69세), 노인(70세 이상)으로 나눈다면
다음과 같습니다.
SELECT CASE WHEN age<20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age>=70 THEN '노인'
ELSE NULL END AS age_class,
COUNT(*)
FROM Persons
GROUP BY CASE WHEN age < 20 THEN '어린이'
WHEN age BETWEEN 20 AND 69 THEN '성인'
WHEN age >=70 THEN '노인'
ELSE NULL END;
age_class | COUNT(*)
어린이 1
성인 6
노인 2
- BMI로 자르기
- BMI 연산은 'weight / POWER(height / 100, 2)'라는 식으로 간단하게 구할 수 있습니다.
-> 이렇게 구한 BMI를 CASE 식으로 구분해 분류합니다.
-> 이를 GROUP BY 구와 SELECT 구에 모두 적어주면 됩니다.
SELECT CASE WHEN weight / POWER(height/100, 2) < 18.5 THEN '저체중'
WHEN 18.5 <= weight / POWER(height / 100, 2)
AND weight / POWER(height / 100, 2) < 25 THEN '정상'
WHEN 25 <= weight / POWER(height / 100, 2) THEN '과체중'
ELSE NULL END AS bmi,
COUNT(*)
FROM Persons
GROUP BY CASE WHEN weight / POWER(height / 100, 2) < 18.5 THEN '저체중'
WHEN 18.5 <= weight / POWER(height / 100, 2)
AND weight / POWER(height / 100, 2) < 25 THEN '정상'
WHEN 25<=weight / POWER(height / 100, 2) THEN '과체중'
ELSE NULL END;
BMI | COUNT(*)
저체중 2
정상 4
과체중 3- GROUP BY 구에는 필드 이름만 적을 수 있다고 생각하는 사람들이 많은데,
이렇게 복잡한 수식을 기준으로도 자를 수 있다는 것을 꼭 기억해야 합니다.
참고
- SQL 레벨업
'DB' 카테고리의 다른 글
| SQL 레벨업 6장 결합 (1) | 2022.04.25 |
|---|---|
| SQL 레벨업 5장 반복문 (2) (1) | 2022.04.25 |
| SQL 레벨업 5장 반복문 (1) (1) | 2022.04.18 |
| SQL 레벨업 3장 SQL의 조건 분기 (1) | 2022.04.11 |
| SQL 레벨업 1장 DBMS 아키텍쳐 (2) | 2022.04.04 |